1 java基础知识
1.2 重载和重写的区别
- 重载:相同的函数名,参数类型不同
- 重写:子类重写父类方法,private修饰的方法不能重写
1.3 string与stringbuild与stringBuffer区别
- String 中由final修饰的char数组实现,故不可变;
- stringBuild比stringBuffer性能好一丢丢;
- StringBuffer为线程安全的,其对方法加了同步锁或者对调用方法加了同步锁
1.4 ==与equals
- == 基本类型比较的是值,对象(引用数据类型)比较的是地址;
- equals() : 未重写的equals方法和==等价,重写之后的equals比较的是对象的值是否相
1.41 为什么重写equals方法,一定要重写HashCode方法
如果你重载了equals,比如说是基于对象的内容实现的,而保留hashCode的实现不变,那么很可能某两个对象明明是“相等”,而hashCode却不一样。
这样,当你用其中的一个作为键保存到hashMap、hasoTable或hashSet中,再以“相等的”找另一个作为键值去查找他们的时候,则根本找不到。
使用HashMap,如果key是自定义的类,就必须重写hashcode()和equals()。
而对于每一个对象,通过其hashCode()方法可为其生成一个整形值(散列码),该整型值被处理后,将会作为数组下标,存放该对象所对应的Entry(存放该对象及其对应值)。 equals()方法则是在HashMap中插入值或查询时会使用到。当HashMap中插入值或查询值对应的散列码与数组中的散列码相等时,则会通过equals方法比较key值是否相等,所以想以自建对象作为HashMap的key,必须重写该对象继承object的hashCode和equals方法。 2.本来不就有hashcode()和equals()了么?干嘛要重写,直接用原来的不行么? HashMap中,如果要比较key是否相等,要同时使用这两个函数!因为自定义的类的hashcode()方法继承于Object类,其hashcode码为默认的内存地址,这样即便有相同含义的两个对象,比较也是不相等的,例如,生成了两个“羊”对象,正常理解这两个对象应该是相等的,但如果你不重写 hashcode()方法的话,比较是不相等的!
HashMap中的比较key是这样的,先求出key的hashcode(),比较其值是否相等,若相等再比较equals(),若相等则认为他们是相等的。若equals()不相等则认为他们不相等。如果只重写hashcode()不重写equals()方法,当比较equals()时只是看他们是否为同一对象(即进行内存地址的比较),所以必定要两个方法一起重写。HashMap用来判断key是否相等的方法,其实是调用了HashSet判断加入元素是否相等。
1.5 final关键字的使用:变量,方法,类
- 变量:修饰基本数据类型,则初始化之后不可更改;修饰引用类型变量,则初始化之后不能让其指向另一个对象。
- 方法:锁定方法,以防任何继承类修改
- 类:表明该类不能被继承,且类中所有方法均被隐式指定为final方法
1.6 object类常见方法
-
public final native Class<?> getClass() //用于返回当前运行时对象的calss对象 public native int hashCode() //返回对象hash码 public boolean equals(Object obj) //比较俩个对象的内存地址是否相等 protected native Object clone() throws CloneNotSupportedExcception // public String toString() //返回类名@实例的哈希码的16进制的字符串 public final native void notify() //唤醒一个在此对象监视器上等待的县城,如果有多个线程在等待只会唤醒一个 public final native void notifyAll() public final native void wait(long timeout) throws InterrupteException //暂停线程的执行。注意:sleep方法没有释放锁,wait方法释放了锁 public final void wait(long timeout,int nanos) throws InterrupteException //nanos表示额外时间 public final void wait() throws InterrupteException //一直等待,没有超时概念 protected void finalize() throws Throwable { } //实例被垃圾回收器回收的时候触发的操作
1.7 java中常见异常
- 所有异常的共同祖先Throwable类,其俩个重要子类: Eception(异常)和Error(错误)
- Error:程序无法处理的错误,大多数与编码者执行操作无关
- Exception:程序本身可以 处理的异常
异常处理:无论异常是否捕获或处理,finally块里的语句都会执行。挡在try或catch块中遇到return语句时,finally语句块将在方法返回之前被执行
注意:以下四种特殊情况finally不会被执行:
- 在finally块语句中发生了异常;
- 在前面的代码中用了System,exit()退出程序;
- 程序坐在线程死亡;
- 关闭CPU。
1.8 java中的俩种输入常用方法
Scanner input = new Scanner(System.in);
String s = input.nextLine(); input.close();
BufferedReader input = new BufferedReader(new InputStreamReader(System.in));
String s = input.readLine();
1.9 接口和抽象类的区别
-
一个类可以实现多个接口;接口中的方法只有声明,不能实现;要实现接口中的所有方法;接口中的实例变量默认是final类型的
接口:接口只有方法体没有具体的实现,用interface修饰
特点:- 接口中没有自己的属性,只能有方法体
- 类在实现接口时,可以实现多个接口
//接口 UserRightsService.java
public interface UserRightsService {
// 获取数据总数
public int findUserRightsCount() throws Exception;
// 根据开始位置,每页记录数查找用户列表
public List<Userrights> selectUserRightsList(int startPos, int pageSize) throws Exception;
// 根据用户权限的id查找一条数据
public Userrights findUserRightsById(int id) throws Exception;
// 根据id更新一条数据
public void updateUserRightsById(int id, String username) throws Exception;
// 根据传过来的参数查询对应参数的数据
public String checkDataByParam(String param, String userloginid) throws Exception;
}
//实现接口 UserRightsServiceImpl.java
public class UserRightsServiceImpl implements UserRightsService {
@Autowired
private UserrightsVoMapper userrightsVoMapper;
// 获取数据总数
public int findUserRightsCount() throws Exception {
return userrightsVoMapper.findUserRightsCount();
}
// 根据开始位置,每页记录数查找用户列表
public List<Userrights> selectUserRightsList(int startPos, int pageSize) throws Exception {
return userrightsVoMapper.selectUserRightsList(startPos, pageSize);
}
// 根据用户权限的id查找一条数据
public Userrights findUserRightsById(int id) throws Exception {
return userrightsVoMapper.findUserRightsById(id);
}
// 根据id更新一条数据
public void updateUserRightsById(int id,String username) throws Exception {
userrightsVoMapper.updateUserRightsById(id,username);
}
// 根据传过来的参数查询对应参数的数据
public String checkDataByParam(String param, String userloginid) throws Exception {
return userrightsVoMapper.checkDataByParam(param, userloginid);
}
-
一个类只能实现一个抽象类,抽象类中可以有非抽象方法;
抽象类:指的是用abstract关键字修饰或者类中有抽象方法,那么这个类就是抽象类
特点:- 抽象类用关键字 abstract修饰
- 抽象类的抽象方法没有方法体,在子类继承父类中有抽象方法时,必须实现抽像方法
- 抽象类不能被实例化
//抽象类 Employee.java
public abstract class Employee{
private String name;
private String address;
private int number;
/*
声明抽象方法会造成以下两个结果:
1.如果一个类包含抽象方法,那么该类必须是抽象类。
2.任何子类必须重写父类的抽象方法,或者声明自身为抽象类。
*/
public abstract double computePay();
public string getName(){
return name;
}
}
//继承抽象类 Salary.java
public class Salary extends Employee{
private double salary; // Annual salary
//任何子类必须重写父类的抽象方法
public double computePay(){
System.out.println("Computing salary pay for " + getName());
return salary/52;
}
}
1.10 (B)IO、NIO、AIO
-
(B)IO:同步阻塞I/O,同步并阻塞,服务器实现模式为一个连接一个线程,即客户端有连接请求时服务器端就需要启动一个线程进行处理,如果这个连接不做任何事情会造成不必要的线程开销,当然可以通过线程池机制改善。并发局限于应用中,在jdk1.4以前是唯一的io
-
NIO:同步非阻塞I/O,服务器实现模式为一个请求一个线程,即客户端发送的连接请求都会注册到多路复用器上,多路复用器轮询到连接有IO请求时才启动一个线程进行处理。NIO方式适用于连接数目多且连接比较短(轻操作)的架构,比如聊天服务器,并发局限于应用中,编程比较复杂,jdk1,4开始支持。
-
AIO:异步非阻塞I/O,服务器实现模式为一个有效请求一个线程,客户端的IO请求都是由操作系统先完成了再通知服务器用其启动线程进行处理。AIO方式适用于连接数目多且连接比较长(重操作)的架构,比如相册服务器,充分调用OS参与并发操作,编程比较复杂,jdk1.7开始支持
同步:如果有多个任务或者事件要发生,这些任务或者事件必须逐个地进行,一个事件或者任务的执行会导致整个流程的暂时等待,这些事件没有办法并发地执行;
异步:如果有多个任务或者事件发生,这些事件可以并发地执行,一个事件或者任务的执行不会导致整个流程的暂时等待。
阻塞 / 非阻塞描述的是函数,指访问某个函数时是否会阻塞线程(block,线程进入阻塞状态)。
同步 /异步描述的是执行IO操作的主体是谁,同步是由用户进程自己去执行最终的IO操作。异步是用户进程自己不关系实际IO操作的过程,只需要由内核在IO完成后通知它既可,由内核进程来执行最终的IO操作。
https://blog.csdn.net/z15732621582/article/details/78939122?tdsourcetag=s_pctim_aiomsg
1 ) 异步非阻塞例子:(网上看到的比较短小精悍的好例子,直接拿过来了)老张爱喝茶,废话不说,煮开水。
出场人物:老张,水壶两把(普通水壶,简称水壶;会响的水壶,简称响水壶)。
1 老张把水壶放到火上,原地不动等水开。(同步阻塞) ---------->老张觉得自己有点傻
2 老张把水壶放到火上,去客厅看毛骗,时不时去看看水开没有。(同步非阻塞) ---------->老张觉得自己有点傻
于是变高端了,买了把会响笛的那种水壶。水开之后,能大声发出嘀~~~~的响声。
3 老张把响水壶放到火上,立等水开。(异步阻塞) --------->老张觉得自己有点傻
4 老张把响水壶放到火上,去客厅看毛骗,水壶响之前不再去看它,响了再去拿壶。(异步非阻塞)
---------->嗯,老张觉得自己棒棒哒
2 java容器
2.1 Arraylist与LinkList的异同
-
ArrayList初始化长度为10,每次扩容为原来的1.5倍。
-
均为线程不安全的
-
Arraylist底层采用Object数组实现;LinkedList采用双向链表数据结构实现
-
Arraylist插入默认追加到末尾,时间复杂度为O(1),若插入到指定位置,就需要将指定位置后的所有元素后移一位;LinkList插入时间复杂恒为O(1)
-
快速随机访问
-
空间占用
//RandomAccess接口中什么都没有定义,可以理解为一个是否具有随机访问功能的标识 public interface RandomAccess{ }迭代器模式:就是提供一种方法对一个容器对象中的各个元素进行访问,而又不暴露该对象容器的内部细节。
2.2 Vector类
- Vector类和ArrayList类似,都是由动态数组实现;
- 是线程安全的,它的方法之间是线程同步的。
- Vector扩容时增长为原来的2倍,ArrayList扩容为原来的1.5倍
2.3 hashmap
- JDK1.8 之前 HashMap 底层是 数组和链表 结合在一起使用也就是 链表散列。HashMap 通过 key 的 hashCode 经 过扰动函数处理过后得到 hash 值,然后通过 (n - 1) & hash 判断当前元素存放的位置(这里的 n 指的是数组的 长度),如果当前位置存在元素的话,就判断该元素与要存入的元素的 hash 值以及 key 是否相同,如果相同的 话,直接覆盖,不相同就通过拉链法解决冲突。
所谓扰动函数指的就是 HashMap 的 hash 方法。使用 hash 方法也就是扰动函数是为了防止一些实现比较差的 hashCode() 方法 换句话说使用扰动函数之后可以减少碰撞。 - HashMap:它根据键的hashCode值存储数据,大多数情况下可以直接定位到它的值,因而具有很快的访问速度,但遍历顺序却是不确定的。 HashMap最多只允许一条记录的键为null,允许多条记录的值为null。HashMap非线程安全,即任一时刻可以有多个线程同时写HashMap,可能会导致数据的不一致。如果需要满足线程安全,可以用 Collections的synchronizedMap方法使HashMap具有线程安全的能力,或者使用ConcurrentHashMap.
2.4 java集合总结
Collection
-
List
- ArrayList:Objct数组实现
- Vector:Object实现,线程安全
- LinkList:双向链表
-
Set
- HashSet:基于hashmap实现, 无序、唯一
- LinkedHashSet:继承 HashSet,内部为LinkedHashMap实现
- TreeSet:红黑树,有序、唯一
Map
Hashmap:数组+链表+红黑树
LinkedHashMap:继承HashMap,双向链表+数组,插入有序或访问有序
HashTable:synchronized同步的HashMap
TreeMap:红黑树
3 java 多线程关键字
3.1 synchronized关键字
- 修饰实例方法,作用于当前对象实例加锁,进入同步代码前要获得当前对象实例的锁。
- 修饰静态方法,作用于当前类对象加锁,进入同步代码前要获得当前类对象的锁。也就是给当前类加锁,会作用于类的所有对象实例,因为静态成员不属于任何一个实例对象,是类成员(所以如果一个线程A调用一个实 例对象的非静态 synchronized 方法,而线程B需要调用这个实例对象所属类的静态 synchronized 方法,是允 许的,不会发生互斥现象,因为访问静态 synchronized 方法占用的锁是当前类的锁,而访问非静态 synchronized 方法占用的锁是当前实例对象锁。 )
- 修饰代码块,指定加锁对象,对给定的对象加锁,进入同步代码库前要获得给定对象的锁。(synchronized加到static静态方法和synchronized(class)代码块都是给Class类上锁)
双重校验锁实现对象单例(线程安全)
public class Singleton{
private volatile static Singleton uniqueInstance;
private Singleton(){}
public static Singleton getUniqueInstance(){
if(uniqueInstance==null){
synchronized(Singeton.class){
if(uniqueInstance==null){
uniqueInstance=new Singleton();
}
}
}
return uniqueInstance;
}
}
另外,需要注意 uniqueInstance 采用 volatile 关键字修饰也是很有必要。 uniqueInstance 采用 volatile 关键字修饰也是很有必要的, uniqueInstance = new Singleton(); 这段代码其实是分 为三步执行:1.为 uniqueInstance 分配内存空间 2. 初始化 uniqueInstance 3. 将 uniqueInstance 指向分配的内存地址 但是由于 JVM 具有指令重排的特性,执行顺序有可能变成 1->3->2。指令重排在单线程环境下不会出先问题,但是在 多线程环境下会导致一个线程获得还没有初始化的实例。例如,线程 T1 执行了 1 和 3,此时 T2 调用 getUniqueInstance() 后发现 uniqueInstance 不为空,因此返回 uniqueInstance,但此时 uniqueInstance 还未被 初始化。
使用 volatile 可以禁止 JVM 的指令重排,保证在多线程环境下也能正常运行。
3.2 ReenTrantLock
-
ReenTrantLock 是可重入的,其加锁和解锁是手动操作,比较灵活。而synchronized的加锁解锁过程是隐式的。
-
ReentrantLock lock = new ReentrantLock(true);//可通过传参指定该锁是公平锁还是非公平锁。 //公平锁是指当锁可用时,在锁上等待时间最长的线程将获得锁的使用权
3.3 volatile
- volatile关键字是线程同步的轻量级实现,所以性能肯定比synchronized好。但volatile只能修饰变量,而synchronized关键字能修饰方法和代码块。(synchronized关键字在JavaSE1.6之后进 行了主要包括为了减少获得锁和释放锁带来的性能消耗而引入的偏向锁和轻量级锁以及其它各种优化之后执行 效率有了显著提升,实际开发中使用 synchronized 关键字的场景还是更多一些。 )
- volatile关键字能保证数据的可见性,单不能保证数据的原子性,synchronized两者都能保证。
- volatile主要用于解决变量在多个线程之间的可见性,而synchronized解决的是多个线程之间访问资源的同步性。
3.4 使用线程池的优点
- 降低资源消耗。 通过重复利用已创建的线程降低线程创建和销毁造成的消耗。
- 提高响应速度。 当任务到达时,任务可以不需要的等到线程创建就能立即执行。
- 提高线程的可管理性。 线程是稀缺资源,如果无限制的创建,不仅会消耗系统资源,还会降低系统的稳定性, 使用线程池可以进行统一的分配,调优和监控。
3.5 实现Runnable接口与Callable接口的区别
Runnable接口不会返回结果;Callable接口可以返回结果。
3.6 execute()方法和submit()方法有什么区别
- execute() 方法用于提交不需要返回值的任务,所以无法判断任务是否被线程池执行成功
- submit()方法用于提交需要返回值的任务。线程池会返回一个future类型的对象,通过该对象可以判断任务是否成功执行。
3.7 如何创建线程池
《阿里巴巴Java开发手册》中强制线程池不允许使用 Executors 去创建,而是通过 ThreadPoolExecutor 的方式,这样的处理方式让写的同学更加明确线程池的运行规则,规避资源耗尽的风险。
方式一:通过构造方法创建:
ThreadPoolExecutor(
int corePoolSize,//指定线程池中线程的数量
int maximumPoolSize,//最大线程数量
long keepAliveTime,//空闲线程数量超过corePoolSize时,多余线程多久被销毁
TimeUnit unit,//KeepAliveTime的单位
BlockingQueue<Runnable> workQueue,//任务队列
ThreadFactory threadFactory,//线程工厂
RejectedExecutionHandler handler
) //拒绝策略
方式二:通过Executors创建
- FixedThreadPool:返回固定线程数量的线程池。
- SingleThreadExecutor:返回一个只有一个线程的线程池。
- CachedThreadPool:该方法返回一个可根据实际情况调整线程数量的线程池。线程池的线程数量不确定,但 若有空闲线程可以复用,则会优先使用可复用的线程。若所有线程均在工作,又有新的任务提交,则会创建新 的线程处理任务。所有线程在当前任务执行完毕后,将返回线程池进行复用。
3.8 Atomic原子类
并发包java.util.concurrent的原子类都放在java.util.concurrent.atomic下,JUC包中的原子类包含四类:
1. 基本类型:使用院子的方式更新基本类型
- AtomicInteger:整形原子类
- AtomicLong:长整型原子类
- AtomicBoolean:布尔型原子类
2. 数组类型:使用院子方式是更新数数组里的某个元素
- AtomicIntegerArray:整形数组原子类
- AtomicLongArray:长整型数组原子类
- AtomicReferenceArray:引用类型数组原子类
3. 引用类型:
- AtomicReference:引用类型院子类
- AtomicStampedRerence:原子更新引用类型例的字段原子类
- AtomICMarkableReference:原子更新带有标记的引用类型,例:AtomicReferenceArray
4. 对象的属性修改类型:
- AtomicIntegerFieldUpdater:原子更新整形字段的更新器
- AtomicLongFieldUpdater:原子更新长整形字段的更新器
- AtomicStampedReference :原子更新带有版本号的引用类型。该类将整数值与引用关联起来,可用于解决原 子的更新数据和数据的版本号,可以解决使用 CAS 进行原子更新时可能出现的 ABA 问题。
5. AtomicInter类常用方法
常用方法:
public final int get() //获取当前的值
public final int getAndSet(int newValue)//获取当前的值,并设置新的
public final int getAndIncrement()//获取当前的值,并自增
public final int getAndDecrement() //获取当前的值,并自减
public final int getAndAdd(int delta) //获取当前的值,并加上预期的
boolean compareAndSet(int expect, int update) //如果输入的数值等于预期值,则以原子方式将该值设置 为输入值(update)
public final void lazySet(int newValue)//终设置为newValue,使用 lazySet 设置之后可能导致其他线 程在之后的一小段时间内还是可以读到旧的值。
使用示例 :
class AtomicIntegerTest {
private AtomicInteger count = new AtomicInteger(); //使用AtomicInteger之后,不需要对该方法加锁,也可以实现线程安全。
public void increment() {
count.incrementAndGet();
}
public int getCount() {
return count.get();
}
}
3.9 AQS原理
1. 简介(AbstractQueuedSynchronizer)
AQS是一个用来构建锁和同步器的框架,使用AQS能简单且高效的构建出应用广泛的大量的同步器,例如ReentrantLock,Semaphore,其他的注入ReentrantReadWriteLock,SynchronousQueue,FutureTask等皆是基于AQS的,利用AQS我们能轻松的构建出符合需求的同步器。
####2. 原 理
-
AQS的核心思想是,如果被请求的共享资源空闲,则将当前请求资源的线程设置为有效工作线程,并且将共享资源设置为锁定状态。如果被请求的共享资源被占用,那么就需要一套线程阻塞等待以及被唤醒时锁分配的机制,这个机制AQS是用CLH队列锁实现的,即将暂时获取不到锁的线程加入到队列中。
-
CLH(Craig,Landin,and Hagersten)队列是一个虚拟的双向队列(虚拟的双向队列即不存在队列实例,仅 存在结点这几件的关联关系)。AQS是将每条请求共享资源的线程封装成一个CLH锁队列的一个结点(node)来实现锁的分配。)

-
AQS使用一个int成员变量来表示同步状态,通过内置的FIFO队列来完成获取资源线程的排队工作。AQS使用CAS对该同步状态进行原子操作实现对其值得修改。
//volatile修饰的队列头节点 private transient volatile Node head; //volatile修饰的队列尾节点 private transient volatile Node tail; //volatile修饰的同步状态 //state = 0 表示同步状态可用(如果用于锁,表示锁可用) //state = 1 表示同步状态已被占用(锁被占用) private volatile int state;
根据源码可以显然看到,AQS 内部实现了 Node 和 ConditionObject 两个内部类,并且 Node 是使用 static final修饰的静态内部类,可以看到其结构如下:
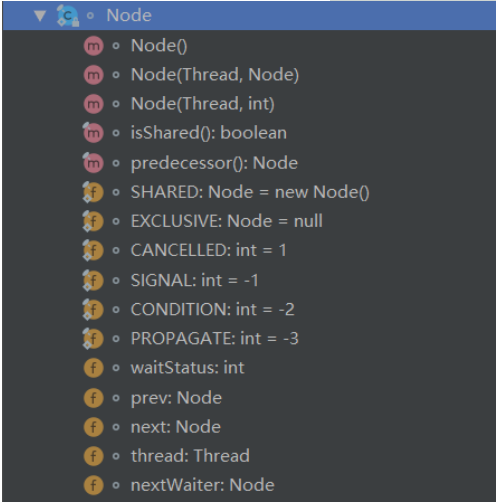
Node 的源码如下:
static final class Node {
//共享模式
static final Node SHARED = new Node();
//独占模式
static final Node EXCLUSIVE = null;
//因为超时或者中断,节点会被设置为取消状态,被取消的节点时不会参与到竞争中的,他会一直保持取消状态不会转变为其他状态;
static final int CANCELLED = 1;
//后继节点的线程处于等待状态,而当前节点的线程如果释放了同步状态或者被取消,将会通知后继节点,使后继节点的线程得以运行
static final int SIGNAL = -1;
//节点在等待队列中,节点线程等待在Condition上,当其他线程对Condition调用了signal()后,改节点将会从等待队列中转移到同步队列中,加入到同步状态的获取中
static final int CONDITION = -2;
//表示下一次共享式同步状态获取将会无条件地传播下去
static final int PROPAGATE = -3;
//等待状态
volatile int waitStatus;
//前驱节点
volatile Node prev;
//后继节点
volatile Node next;
//当前节点的线程
volatile Thread thread;
}
组件
- Semaphore(信号量)-允许多个线程同时访问:synchronized和ReentrantLock都是只允许一个线程访问某个资源,Semaphore可以指定多个线程同时访问某个资源。
- CountDownLatch(倒计时器):是一个同步工具类,用来协调多个线程之间的同步。通常用来控制线程等待,它可以让某一个线程等待直到倒计时结束,再开始执行。
- CyclicBarrier(循环栅栏):CyclicBarrier 和 CountDownLatch 非常类似,它也可以实现线程间的技术等待, 但是它的功能比 CountDownLatch 更加复杂和强大。主要应用场景和 CountDownLatch 类似。CyclicBarrier 的字面意思是可循环使用(Cyclic)的屏障(Barrier)。它要做的事情是,让一组线程到达一个屏障(也可以叫 同步点)时被阻塞,直到后一个线程到达屏障时,屏障才会开门,所有被屏障拦截的线程才会继续干活。 CyclicBarrier默认的构造方法是 CyclicBarrier(int parties),其参数表示屏障拦截的线程数量,每个线程调用 await方法告诉 CyclicBarrier 我已经到达了屏障,然后当前线程被阻塞
-
实现
了解了上面的核心结构,我们就可以继续来研究一下 AQS 内部具体是怎么实现的。
同步器的设计是基于模板方法设计模式的,也就是说,使用者需要继承同步器并重写指定方法,然后将同步器组合在自定义同步组件的实现中,并调用同步器提供的模板方法,而这些模板方法将会调用使用者重写的方法。可能说的有点抽象,后面在探讨 ReentrantLock 等基于 AQS 实现的类中会逐渐明白这个原理。
重写同步器指定的方法时,需要使用同步器提供的如下3个方法来访问或者修改同步状态:
getState():获取当前同步状态。setState(int newState):设置当前同步状态。compareAndSetState(int expect,int update):使用 CAS 设置当前状态,该方法能够保证状态设置的原子性。
其源码实现:
//获取同步状态 protected final int getState() { return state; } //设置同步状态 protected final void setState(int newState) { state = newState; } //以原子方式设置同步状态 protected final boolean compareAndSetState(int expect, int update) { return unsafe.compareAndSwapInt(this, stateOffset, expect, update); }
由于 AQS 里面的方法很多,但是绝大多数方法都是 private 和 final 的,即不能被继承和实现。在第一个 AQS 图中红框圈出来的表示的是继承 AQS 后能够重写的方法,其方法名称和方法描述如下:
| 方法名称 | 描述 |
|---|---|
| protected boolean tryAcquire(int args) | 独占式获取同步状态,实现该方法需要查询当前状态并判断同步状态是否符合预期,然后再进行CAS设置同步状态。 |
| protected boolean tryRelease(int arg) | 独占式释放同步状态 ,等待获取同步状态的线程将有机会获取同步状态 |
| protected int tryAcquireShared | 共享式获取同步状态,返回大于等于0的值表示获取成功,否则获取失败 |
| protected boolean tryReleaseShared(int arg) | 共享式释放同步状态 |
| protected boolean isHeldExclusively() | 当前同步器是否在独占模式下被线程占用,一般该方法表示是否被当前线程独占 |
源码中上面方法如下:
//尝试获取独占模式
protected boolean tryAcquire(int arg) {
throw new UnsupportedOperationException();
}
//尝试释放独占模式
protected boolean tryRelease(int arg) {
throw new UnsupportedOperationException();
}
//共享式获取同步状态
//返回负数表示失败;0表示成功,但没有剩余可用资源;正数表示成功,且有剩余资源。
protected int tryAcquireShared(int arg) {
throw new UnsupportedOperationException();
}
//共享式释放同步状态;如果释放后允许唤醒后续等待结点返回true,否则返回false。
protected boolean tryReleaseShared(int arg) {
throw new UnsupportedOperationException();
}
//当前同步器是否在独占模式下被线程占用,一般该方法表示是否被当前线程所独占;只有用到condition才需要去实现它。
protected boolean isHeldExclusively() {
throw new UnsupportedOperationException();
}
根据上面分析可知,AQS 在内部定义了两种资源共享方式:
- Exclusive(独占,只有一个线程能执行,如ReentrantLock)
- Share(共享,多个线程可同时执行,如Semaphore/CountDownLatch)
下面我们对这两种方式一一探讨。
3.9.1 独占模式
独占模式就相当于使用了排他锁,每次只有一个线程能够执行,其他线程需要在 CLH 队列中排队。下面分析一下 AQS 源码中的独占模式方法。
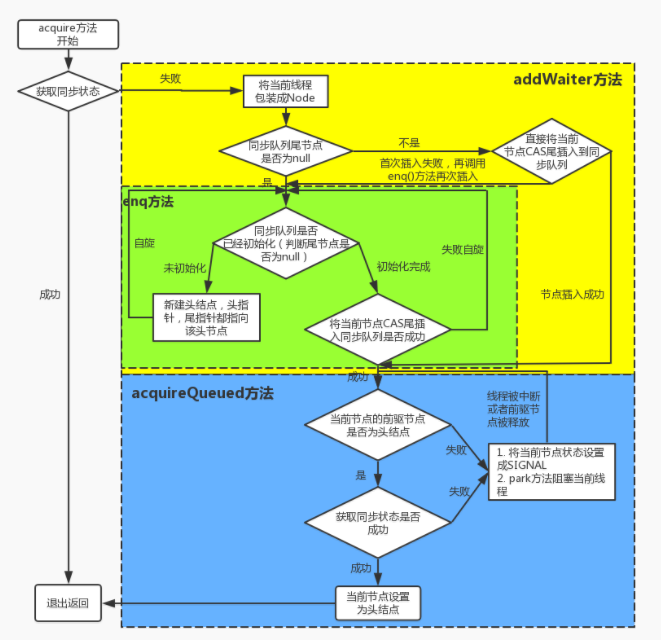
acquire()方法
该方法以独占模式获取共享资源。如果获取到资源,线程直接返回,否则进入等待队列,直到获取到资源为止,且整个过程忽略中断的影响。ReentrantLock的lock方法就是调用的该方法来获取锁。
方法的执行流程如下:
- 调用自定义同步器的
tryAcquire()尝试直接去获取资源,如果成功则直接返回。 - 没成功,则
addWaiter()将该线程加入等待队列的尾部,并标记为独占模式。 acquireQueued()使线程在等待队列中休息,有机会时(轮到自己,会被unpark())会去尝试获取资源。获取到资源后才返回。如果在整个等待过程中被中断过,则返回true,否则返回false。 如果线程在等待过程中被中断过,它是不响应的。只是获取资源后才再进行自我中断selfInterrupt()。
/**
* 独占模式获取同步状态,如果当前线程获取同步状态成功,则直接返回,否则
* 将会进入同步队列等待,该方法会调用实现类重写的tryAcquire(int arg)方法
*/
public final void acquire(int arg) {
if (!tryAcquire(arg) &&
acquireQueued(addWaiter(Node.EXCLUSIVE), arg))
selfInterrupt();
}
tryAcquire()方法
源码 doc 翻译:尝试以独占模式获取。 如果对象的状态允许以独占模式获取它,则此方法应查询,如果是,则获取它。
执行 acquire 的线程始终调用此方法。 如果此方法报告失败,则获取方法可以对线程进行排队(如果它尚未排队),直到它通过某个其他线程的释放来发出信号。 这可用于Lock类中实现tryLock()方法。
addWaiter()方法
源码 doc 翻译:为当前线程和给定模式创建节点并进行排队。
/**
* 将当前线程加入到等待队列的队尾,并返回当前线程所在的结点
*/
private Node addWaiter(Node mode) {
Node node = new Node(Thread.currentThread(), mode);
// 首先尝试在链表的后面快速添加节点
Node pred = tail;
if (pred != null) {
node.prev = pred;
// 将该节点添加到队列尾部
if (compareAndSetTail(pred, node)) {
pred.next = node;
return node;
}
}
// 如果首节点为空或者CAS添加失败,则进入enq方法通过自旋方式入队列,确保一定成功,这是一个保底机制
enq(node);
return node;
}
enq()方法
源码 doc 翻译:将节点插入队列,必要时进行初始化 。
通过自旋锁的方式来保证节点可以正确添加,只有成功添加后,当前线程才会从该方法返回,否则会一直执行下去 。
/**
* 将node加入队尾
*/
private Node enq(final Node node) {
// 自旋
for (;;) {
Node t = tail;
// 当前没有节点,构造一个new Node(),将head和tail指向它
if (t == null) {
if (compareAndSetHead(new Node()))
tail = head;
} else {
// 当前有节点,将传入的Node放在链表的最后
node.prev = t;
if (compareAndSetTail(t, node)) {
t.next = node;
return t;
}
}
}
}
acquireQueued()方法
源码doc翻译:对于已经在队列中的线程,以独占不间断模式获取。 由条件等待方法使用以及获取。
通过tryAcquire()和addWaiter(),该线程获取资源失败,已经被放入等待队列尾部了。下一步需要处理的是:进入等待状态休息,直到其他线程彻底释放资源后唤醒自己,自己再拿到资源,然后就可以去干自己想干的事了。其实就是个排队拿号,在等待队列中排队拿号,直到拿到号后再返回 。
final boolean acquireQueued(final Node node, int arg) {
boolean failed = true;
try {
boolean interrupted = false; // 标记等待过程中是否被中断过
for (;;) {
final Node p = node.predecessor(); // node的前一个节点
// 如果前一个节点是head,说明当前node节点是第二个节点,接着尝试去获取资源
// 可能是head释放完资源唤醒自己的,当然也可能被interrupt了
if (p == head && tryAcquire(arg)) {
setHead(node);
p.next = null; // help GC
failed = false;
return interrupted; // 返回等待过程中是否被中断过
}
// 如果自己可以休息了,就进入waiting状态,直到被unpark()
if (shouldParkAfterFailedAcquire(p, node) &&
parkAndCheckInterrupt())
interrupted = true; // 如果等待过程中被中断过,哪怕只有那么一次,就将interrupted标记为true
}
} finally {
if (failed)
cancelAcquire(node);
}
}
shouldParkAfterFailedAcquire()方法
源码 doc 翻译:检查并更新无法获取的节点的状态。 如果线程应该阻塞,则返回 true。 这是所有获取循环中的主要信号控制。 需要pred == node.prev。
此方法主要用于检查状态,看看自己是否真的可以去休息了
- 如果 pred 的
waitStatus是SIGNAL,直接返回true - 如果 pred 的
waitStatus>0,也就是CANCELLED,向前一直找到<= 0的节点,让节点的next指向node - 如果 pred 的
waitStatus<=0,改成SIGNAL
private static boolean shouldParkAfterFailedAcquire(Node pred, Node node) {
int ws = pred.waitStatus;
if (ws == Node.SIGNAL)
// 如果已经告诉前驱拿完号后通知自己一下,那就可以一边玩蛋去了
return true;
if (ws > 0) {
/*
* 如果前节点放弃了,那就一直往前找,直到找到最近一个正常等待的状态,并排在它的后边。
* 注意:那些放弃的结点,由于被自己“加塞”到它们前边,它们相当于形成一个无引用链,稍后就会被GC回收
*/
do {
node.prev = pred = pred.prev;
} while (pred.waitStatus > 0);
pred.next = node;
} else {
// 如果前节点正常,那就把前节点的状态设置成SIGNAL,告诉它拿完号后通知下。
compareAndSetWaitStatus(pred, ws, Node.SIGNAL);
}
return false;
}
parkAndCheckInterrupt()方法
/**
* 让线程去休息,真正进入等待状态
*/
private final boolean parkAndCheckInterrupt() {
LockSupport.park(this); // 调用park()使线程进入waiting状态
return Thread.interrupted(); // 如果被唤醒,查看是否被中断(该方法会重置标识位)
}
acquireQueued总共做了3件事:
- 结点进入队尾后,检查状态。
- 调用
park()进入waiting 状态,等待unpark()或interrupt()唤醒自己。 - 被唤醒后,看自己是不是有资格能拿到号。如果拿到,head 指向当前结点,并返回从入队到拿到号的整个过程中是否被中断过;如果没拿到,继续流程 1。
流程图如下:
release()方法
此方法是独占模式下线程释放资源的顶层入口。它会释放指定量的资源,如果彻底释放了(即 state=0),它会唤醒等待队列里的其他线程来获取资源 。
/**
* 释放资源
*/
public final boolean release(int arg) {
if (tryRelease(arg)) {
Node h = head;
if (h != null && h.waitStatus != 0)
unparkSuccessor(h); // 唤醒等待队列里的下一个线程
return true;
}
return false;
}
tryRelease()方法
跟tryAcquire()一样,这个方法是需要独占模式的自定义同步器去实现的。正常来说,tryRelease()都会成功的,因为这是独占模式,该线程来释放资源,那么它肯定已经拿到独占资源了,直接减掉相应量的资源即可(state-=arg),也不需要考虑线程安全的问题。但要注意它的返回值,上面已经提到了,release()是根据tryRelease()的返回值来判断该线程是否已经完成释放掉资源了!所以自义定同步器在实现时,如果已经彻底释放资源(state=0),要返回 true,否则返回 false。
unparkSuccessor()方法
private void unparkSuccessor(Node node) {
// 这里,node一般为当前线程所在的结点。
int ws = node.waitStatus;
if (ws < 0) // 置零当前线程所在的结点状态,允许失败。
compareAndSetWaitStatus(node, ws, 0);
// 找到下一个需要唤醒的结点s
Node s = node.next;
if (s == null || s.waitStatus > 0) {
s = null;
for (Node t = tail; t != null && t != node; t = t.prev)
if (t.waitStatus <= 0)
s = t;
}
if (s != null)
LockSupport.unpark(s.thread); // 唤醒
}
总结一下
在 AQS 中维护着一个 FIFO 的同步队列,当线程获取同步状态失败后,则会加入到这个 CLH 同步队列的对尾并一直保持着自旋。在 CLH 同步队列中的线程在自旋时会判断其前驱节点是否为首节点,如果为首节点则不断尝试获取同步状态,获取成功则退出 CLH 同步队列。当线程执行完逻辑后,会释放同步状态,释放后会唤醒其后继节点。
3.9.2共享模式
acquireShared()方法
源码 doc 翻译:以共享模式获取,忽略中断。 通过首先调用{@link #tryAcquireShared}来实现,成功返回。 否则线程排队,可能反复阻塞和解除阻塞,调用{@link #tryAcquireShared}直到成功。
简单点说就是这个方法会获取指定量的资源,获取成功则直接返回,获取失败则进入等待队列,直到获取到资源为止,整个过程忽略中断。
public final void acquireShared(int arg) {
if (tryAcquireShared(arg) < 0)
doAcquireShared(arg);
}
tryAcquireShared()方法
tryAcquireShared()依然需要自定义实现类去实现。但是 AQS 已经把其返回值的语义定义好了:负值代表获取失败;0 代表获取成功,但没有剩余资源;正数表示获取成功,还有剩余资源,其他线程还可以去获取。
//共享式获取同步状态
protected int tryAcquireShared(int arg) {
throw new UnsupportedOperationException();
}
doAcquireShared()方法
源码 doc 翻译:以共享不间断模式获取
此方法用于将当前线程加入等待队列尾部休息,直到其他线程释放资源唤醒自己,自己成功拿到相应量的资源后才返回。
private void doAcquireShared(int arg) {
//队列尾部添加共享模式的节点
final Node node = addWaiter(Node.SHARED);
boolean failed = true;
try {
boolean interrupted = false;
for (;;) {
final Node p = node.predecessor();
if (p == head) {
//获取上一个节点,如果上一个节点时head,尝试获取资源
int r = tryAcquireShared(arg);
if (r >= 0) {
setHeadAndPropagate(node, r);//成功有剩余资源,将head指向自己,唤醒之后的线程
p.next = null; // help GC
if (interrupted)
selfInterrupt();
failed = false;
return;
}
}
if (shouldParkAfterFailedAcquire(p, node) &&
parkAndCheckInterrupt())
interrupted = true;
}
} finally {
if (failed)
cancelAcquire(node);
}
}
setHeadAndPropagate()方法
设置队列头,并检查后继者是否在共享模式下等待,如果是传播,如果传播> 0或PROPAGATE状态已设置。
这个方法除了重新标记 head 指向的节点外,还有一个重要的作用,那就是 propagate(传递)。
private void setHeadAndPropagate(Node node, int propagate) {
Node h = head; // Record old head for check below
setHead(node);
/*
* Try to signal next queued node if:
* Propagation was indicated by caller,
* or was recorded (as h.waitStatus either before
* or after setHead) by a previous operation
* (note: this uses sign-check of waitStatus because
* PROPAGATE status may transition to SIGNAL.)
* and
* The next node is waiting in shared mode,
* or we don't know, because it appears null
*
* The conservatism in both of these checks may cause
* unnecessary wake-ups, but only when there are multiple
* racing acquires/releases, so most need signals now or soon
* anyway.
*/
if (propagate > 0 || h == null || h.waitStatus < 0 ||
(h = head) == null || h.waitStatus < 0) {
Node s = node.next;
if (s == null || s.isShared())
doReleaseShared();
}
}
doReleaseShared()方法
共享模式的释放操作 ,发出后续信号并确保传播。 (注意:对于独占模式,如果需要信号,只需调用数量来调用 head 的 unparkSuccessor)
private void doReleaseShared() {
/*
* Ensure that a release propagates, even if there are other
* in-progress acquires/releases. This proceeds in the usual
* way of trying to unparkSuccessor of head if it needs
* signal. But if it does not, status is set to PROPAGATE to
* ensure that upon release, propagation continues.
* Additionally, we must loop in case a new node is added
* while we are doing this. Also, unlike other uses of
* unparkSuccessor, we need to know if CAS to reset status
* fails, if so rechecking.
*/
for (;;) {
Node h = head;
if (h != null && h != tail) {
int ws = h.waitStatus;
if (ws == Node.SIGNAL) {
if (!compareAndSetWaitStatus(h, Node.SIGNAL, 0))
continue; // loop to recheck cases
unparkSuccessor(h);
}
else if (ws == 0 &&
!compareAndSetWaitStatus(h, 0, Node.PROPAGATE))
continue; // loop on failed CAS
}
if (h == head) // loop if head changed
break;
}
}
acquireShared总结:
tryAcquireShared()尝试获取资源,成功则直接返回。doAcquireShared()会将当前线程加入等待队列尾部休息,直到其他线程释放资源唤醒自己。它还会尝试着让唤醒传递到后面的节点。
releaseShared()方法
以共享模式发布。, 如果{@link #tryReleaseShared}返回 true,则通过解除阻塞一个或多个线程来实现。
public final boolean releaseShared(int arg) {
if (tryReleaseShared(arg)) {
doReleaseShared();
return true;
}
return false;
}
4 java虚拟机
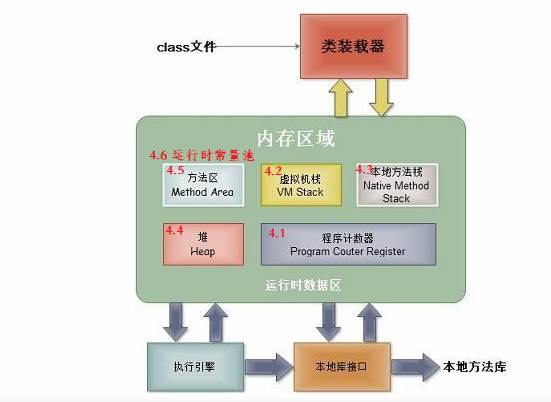
4.1 程序计数器
- 线程私有。程序计数器是一块较小的内存空间,他的作用可以看做是当前线程所执行的字节码的行号指示器,在虚拟机的概念模型里,字节码解释器工作时就是通过改变计数器的值来选择下一个需要执行的字节码指令,分支、循环、跳转、异常处理、线程恢复等基础功能都需要依赖计数器。
- java虚拟机的多线程是通过线程轮流切换并分配处理器执行时间的方式来实现的,在任何一个确定的时刻,一个处理器只会执行一条线程中的指令。因此,为了线程切换后能恢复到正确的执行位置,每条线程都需要一个独立的程序计数器。
- 如果线程执行的是一个java方法,这个计数器记录的是正在执行的虚拟机字节码指令地址;如果正在执行的是native方法,则计数值为空(undefined)
4.2 java 虚拟机栈
- 线程私有,描述的是java方法执行的内存模型,生命周期与线程周期相同。每个方法执行时都会创建一个栈帧用于存储局部变量、操作栈、动态链接、方法出口等信息,每个方法被调用直至执行完成过程,对应一个栈帧在虚拟机栈中从入栈到出栈的过程。
4.3 本地方法栈
跟4.2类同
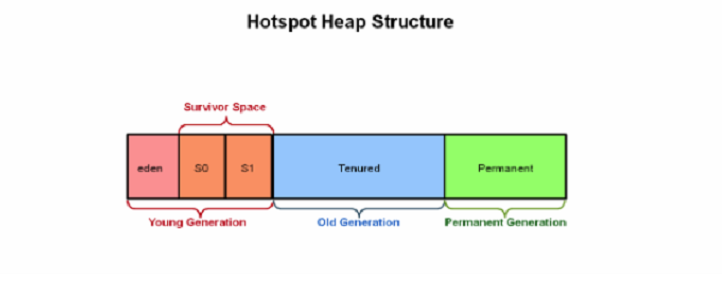
4.4 java堆
- 对大多数应用来说,java堆是java虚拟机所管理的内存中最大的一块。java堆是被所有线程共享的一块内存区域,在虚拟机启动时创建。此区域的唯一目的就是存放对象实例,几乎所有的对象实例都在这里分配内存。
- 是垃圾收集器管理的主要区域,因此很多时候也被称为“GC堆”,从内存 回收的角度看,现在收集器基本都是采用分代收集算法,所以java堆中还可以详细分为:新生代和老年代等
- java堆傻可以处于物理上不连续的内存空间中,只要逻辑上是连续的即可,当前主流虚拟机都是按照可拓展来实现的,通过该-Xms初始化堆,-Xmx最大堆空间
4.5 方法区
是各个线程共享的内存区域,用于存储已经被虚拟机加载的类信息,常量,静态变量,即时编译后的代码等数据。
4.6 运行时常量池
-
方法区的一部分分。class文件中除了有类的版本,方法,字段,接口等描述信息外,还有一项是常量池,用于存放编译期生成的各种字面量和符号引用,这部分内容将在类加载后存放到方法区的运行时常量池中。
-
运行时常量池相对于Class文件常量池的另外一个重要特征是具备动态性, Java语言并不要求常量一定只能在编译期产生, 也就是并非预置入Class文件中常量池的内容才能进入方法区运行时常量池, 运行期间也可能将新的常量放入翅中, 这种特性被开发人员利用的比较多的便是String类的intern() 方法.intern方法还是会先去查询常量池中是否有已经存在,如果存在,则返回常量池中的引用,这一点与之前没有区别,区别在于,如果在常量池找不到对应的字符串,则不会再将字符串拷贝到常量池,而只是在常量池中生成一个对原字符串的引用。
4.7 垃圾回收机制
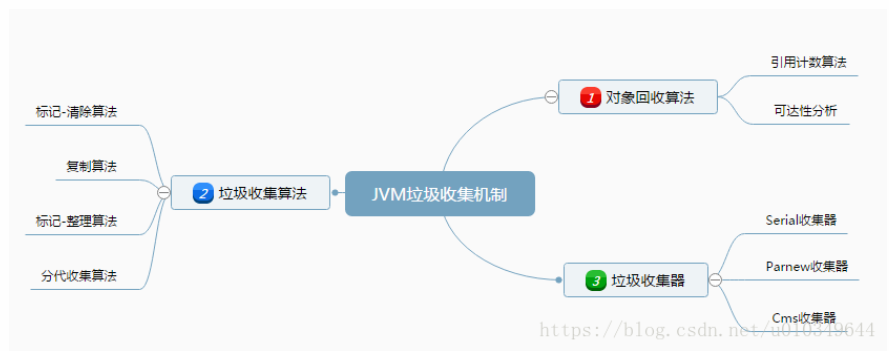
4.7.1 对象回收算法
1. 引用计数算法。
- 核心思路为,给每个对象添加一个被引用计数器,被引用时+1,引用失效-1,等于0时表示该对象没有被引用,可以被回收。FlashPlayer/Python使用该算法,简单高效。但是,Java/C#并不采用该算法,因为该算法没有解决对象相互引用的问题,即:当两个对象相互引用且不被其它对象引用时,各自的引用计数为1,虽不为0,但仍然是可被回收的垃圾对象。
2. 可达分析法。
-
程序把所有的引用关系看作一张图,通过一系列的名为GC Roots的对象作为起始点,从这些节点开始向下搜索,搜索所走过的路径称为引用链。当一个对象到 GC Roots 没有任何引用链相连(就是从 GC Roots 到这个对象不可达)时,则证明此对象是不可用的。
-
1会在cpu空闲的时候自动进行回收 2在堆内存存储满了之后 3主动调用System.gc()后尝试进行回收
4.7.2 垃圾回收算法
1. 标记清除算法
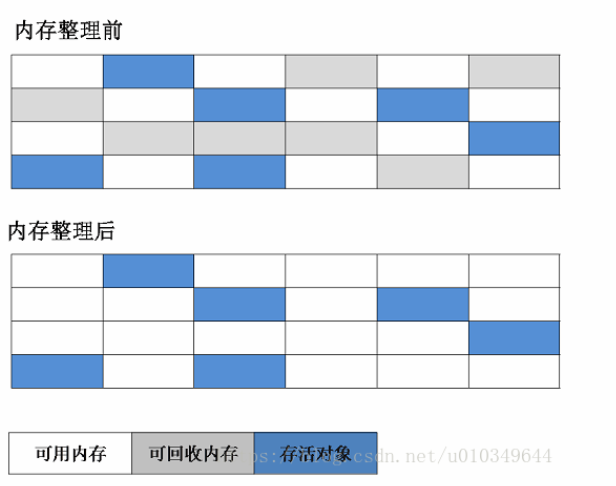
标记-清除(Mark-Sweep)算法可以算是最基础的垃圾收集算法,该算法主要分为“标记”和“清除”两个阶段。先标记可以被清除的对象,然后统一回收被标记要清除的对象,这个标记过程采用的就是可达性分析算法。
标记清除算法最大的缺点是在垃圾回收之后会产生大量的内存碎片,而如果内存碎片多了,当我们再创建一个占用内存比较大的对象时就没有足够的内存来分配,那么这个时候虚拟机就还要再次触发GC来清理内存后来给新的对象分配内存。
2. 复制算法
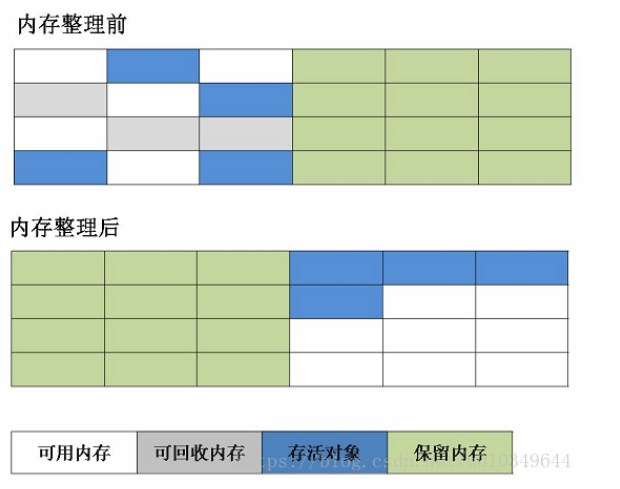
为了解决效率问题及标记清除算法的缺点,一种称为“复制”(Copying)的收集算法出现了,它将可用内存按容量划分为大小相等的两块,每次只使用其中一块,当这一块用完了,触发GC操作将存活的对象复制到另一个区域当中,然后再把使用过的内存空间一次清理掉。这样使得每次都对整个半区进行内存回收,内存分配也不用考虑内存碎片的问题,只要移动堆顶指针,按顺序分配内存即可,实现简单,运行高效。
这种算法最大的缺点是将原有内存分成了两块,每次只能使用区中一块,也就是损失了50%的内存空间,代价有点大。
3. 标记-整理算法
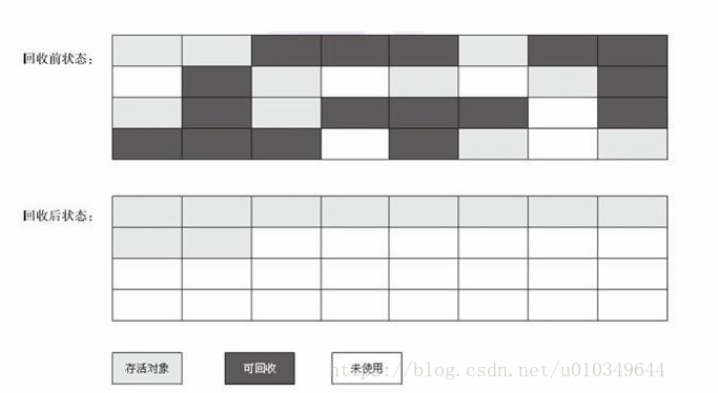
复制算法在对象存活率较高的情况下需要进行较多的复制操作,这样效率也会变低,更关键的是还需要浪费50%的内存空间,为了解决这些问题,于是“标记-整理”(Mark-Compact)算法就出来了,标记过程仍然使用可达性算法来判断,后续步骤不是直接对可回收对象进行清理,而是让所有存活的对象向一端移动,然后直接清理边界以外的内存。标记-整理算法比较适合年老代的算法实现
4. 分代收集算法
当前商业虚拟机的垃圾回收都是采用“分代收集”(Generational Collection)算法,这种算法其实并没有什么新的思想,只是根据对象的存活周期的不同将内存划分为几块。一般把Java堆分为新生代和老年代,然后根据不同年代的特点采用适当的收集算法。
1、在新生代中,每次垃圾收集时都发现有大批对象死去,只有少量存活,那就选用复制算法。只需要付出少量存活对象的复制成本就可以完成收集。
2、老年代中因为对象存活率高、没有额外空间对他进行分配担保,就必须用标记-清除或者标记-整理。
4.7.3 垃圾收集器
1 Serial收集器
-
特性:
最基本、发展历史最久的收集器,采用复制算法的单线程收集器,**单线程一方面意味着它只会使用一个CPU或一条线程去完成垃圾收集工作,另一方面也意味着在它进行垃圾收集时,必须暂停其他所有的工作线程,直到它收集结束为止,这个过程也称为 Stop The world。**后者意味着,在用户不可见的情况下要把用户正常工作的线程全部停掉,这显然对很多应用是难以接受的。 -
应用场景:
Serial收集器依然是虚拟机运行在Client模式下的默认新生代收集器。 在用户的桌面应用场景中,可用内存一般不大(几十M至一两百M),可以在较短时间内完成垃圾收集(几十MS至一百多MS),只要不频繁发生,这是可以接受的 -
优势:
简单而高效(与其他收集器的单线程相比),对于限定单个CPU的环境来说,Serial收集器由于没有线程交互的开销,专心做垃圾收集自然可以获得最高的单线程收集效率。比如在用户的桌面应用场景中,可用内存一般不大(几十M至一两百M),可以在较短时间内完成垃圾收集(几十MS至一百多MS),只要不频繁发生,这是可以接受的。"-XX:+UseSerialGC":添加该参数来显式的使用串行垃圾收集器;
2 ParNew收集器
- 特性: ParNew收集器其实就是Serial收集器的多线程版本,除了使用多条线程进行垃圾收集外,其余行为和Serial收集器完全一样,包括Serial收集器可用的所有控制参数、收集算法、Stop The world、对象分配规则、回收策略等都一样。在实现上也共用了相当多的代码。
- 应用场景:
ParNew收集器是许多运行在Server模式下的虚拟机中首选的新生代收集器。很重要的原因是:除了Serial收集器之外,目前只有它能与CMS收集器配合工作(看图)。在JDK1.5时期,HotSpot推出了一款几乎可以认为具有划时代意义的垃圾收集器-----CMS收集器,这款收集器是HotSpot虚拟机中第一款真正意义上的并发收集器,它第一次实现了让垃圾收集线程与用户线程同时工作。 - 优势:
在单CPU中的环境中,不会比Serail收集器有更好的效果,因为存在线程交互开销,甚至由于线程交互的开销,该收集器在两个CPU的环境中都不能百分百保证可以超越Serial收集器。当然,随着可用CPU数量的增加,它对于GC时系统资源的有效利用还是很有好处的,它默认开启的收集线程数与CPU数量相同。
设置参数:****"-XX:+UseConcMarkSweepGC":指定使用CMS后,会默认使用ParNew作为新生代收集器;"-XX:+UseParNewGC":强制指定使用ParNew; "-XX:ParallelGCThreads":指定垃圾收集的线程数量,ParNew默认开启的收集线程与CPU的数量相同;
3 Parallel Scavenge 收集器
- 特性: Parallel Scavenge收集器是一个新生代收集器,它也是使用复制算法的收集器,也是并行的多线程收集器。
- 对比分析:
- Parallel Scavenge收集器 VS CMS等收集器:
Parallel Scavenge收集器的特点是它的关注点与其他收集器不同,CMS等收集器的关注点是尽可能地缩短垃圾收集时用户线程的停顿时间,而Parallel Scavenge收集器的目标则是达到一个可控制的吞吐量(Throughput)。
由于与吞吐量关系密切,Parallel Scavenge收集器也经常称为“吞吐量优先”收集器。 - Parallel Scavenge收集器 VS ParNew收集器:
Parallel Scavenge收集器与ParNew收集器的一个重要区别是它具有自适应调节策略。
- Parallel Scavenge收集器 VS CMS等收集器:
- 应用场景:
Parallel Scavenge收集器是虚拟机运行在Server模式下的默认垃圾收集器。
停顿时间短适合需要与用户交互的程序,良好的响应速度能提升用户体验;高吞吐量则可以高效率利用CPU时间,尽快完成运算任务,主要适合在后台运算而不需要太多交互的任务。
该收集器以高吞吐量为目标,就是减少垃圾收集时间,从而让用户代码获得更长的运行时间。所以适合那些运行在多个CPU上,并且专注于后台计算的应用程序,例如:执行批量处理任务、订单处理,工资支付,科学计算等。
设置参数:
虚拟机提供了-XX:MaxGCPauseMillis和-XX:GCTimeRatio两个参数来精确控制最大垃圾收集停顿时间和吞吐量大小。不过不要以为前者越小越好,GC停顿时间的缩短是以牺牲吞吐量和新生代空间换取的。
"-XX:+MaxGCPauseMillis":控制最大垃圾收集停顿时间,大于0的毫秒数;这个参数设置的越小,停顿时间可能会缩短,但也会导致吞吐量下降,导致垃圾收集发生得更频繁。
"-XX:GCTimeRatio":设置垃圾收集时间占总时间的比率,0<n<100的整数,就相当于设置吞吐量的大小。垃圾收集执行时间占应用程序执行时间的比例的计算方法是: 1 / (1 + n)例如,选项-XX:GCTimeRatio=19,设置了垃圾收集时间占总时间的5%--1/(1+19);默认值是1%--1/(1+99),即n=99;垃圾收集所花费的时间是年轻一代和老年代收集的总时间;
GC自适应的调节策略:
Parallel Scavenge收集器有一个参数-XX:+UseAdaptiveSizePolicy。当这个参数打开之后,就不需要手工指定新生代的大小、Eden与Survivor区的比例、晋升老年代对象年龄等细节参数了,虚拟机会根据当前系统的运行情况收集性能监控信息,动态调整这些参数以提供最合适的停顿时间或者最大的吞吐量,这种调节方式称为GC自适应的调节策略(GC Ergonomics)。如果对于垃圾收集器运作原理不太了解,以至于在优化比较困难的时候,使用Parallel收集器配合自适应调节策略,把内存管理的调优任务交给虚拟机去完成将是一个不错的选择。
4 CMS收集器
-
CMS(Concurrent Mark Sweep)收集器是一种以获取最短回收停顿时间为目标的收集器。
-
目前很大一部分的Java应用集中在互联网站或者B/S系统的服务端上,这类应用尤其重视服务的响应速度,希望系统停顿时间最短,以给用户带来较好的体验。CMS收集器就非常符合这类应用需求。
-
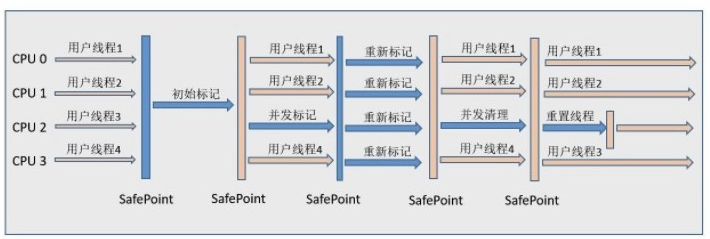
从名字(包含“Mark Sweep”)上就可以看出,CMS收集器是基于“标记-清除”算法实现的,它的运作过程相对于前面几种收集器来说更复杂一些,整个过程分为4个步骤,包括:
- 初始标记(CMS initial mark)
- 并发标记(CMS concurrent mark)
- 重新标记(CMS remark)
- 并发清除(CMS concurrent sweep)
-
其中,初始标记、重新标记这两个步骤仍然需要“Stop The World”。1.初始标记仅仅只是标记一下GC Roots能直接关联到的对象,速度很快;2.并发标记阶段就是进行GC Roots Tracing的过程;3.重新标记阶段是为了修正并发标记期间因用户程序继续运作而导致标记产生变动的那一部分对象的标记记录,这个阶段的停顿时间一般会比初始标记阶段稍长一些,但远比并发标记的时间短。
-
由于整个过程中耗时最长的并发标记和并发清除过程收集器线程都可以与用户线程一起工作,所以,从总体上来说,CMS收集器的内存回收过程是与用户线程一起并发执行的。通过下图可以比较清除看见CMS收集器的运作步骤中并发和需要停顿的时间。
**优点:**并发收集、低停顿。
缺点:
-
CMS收集器对CPU资源非常敏感。
- 其实,面向并发设计的程序都对CU资源比较敏感。在并发阶段,它虽然不会导致用户线程停顿,但是会因为占用了一部分线程(或者说CPU资源)而导致应用程序变慢,总吞吐量会降低。
- CMS默认启动的回收线程数是(CPU数量+3)/ 4,也就是当CPU在4个以上时,并发回收时垃圾收集线程不少于25%的CPU资源,并且随着CPU数量的增加而下降。
- 但是当CPU不足4个(譬如2个)时,CMS对用户程序的影响就可能变得更大,如果本来CPU负载比较大,还分出一半的运算能力去执行收集器线程,就可能导致用户程序的执行速度忽然降低了50%,其实也让人无法接受。
- 为了应付这种情况,虚拟机提供了一种称为“增量式并发收集器”的CMS收集器变种,所做的事情和单CPU年代PC机操作系统使用抢占式来模拟多任务机制的思想一样,就是在并发标记、清理的时候让GC线程、用户线程交替运行,尽量减少GC线程的独占资源的时间,这样整个垃圾收集的过程会更长,但对用户程序的影响就会显得少一些,也就是速度下降没有那么明显。
- 实践证明,增量时的CMS收集器效果很一般,在目前版本中,i-CMS已经被声明为“deprecated”,即不再提倡用户使用。
-
CMS收集器无法处理浮动垃圾,可能出现“Concurrent Mode Failure”失败而导致另一次Full GC的产生。
- 由于CMS并发清理阶段用户线程还在运行着,伴随程序运行自然就还会有新的垃圾不断产生,这一部分垃圾出现在标记过一部分垃圾就称为“浮动垃圾”。
- 也是由于垃圾收集阶段用户线程还需要运行,那也就需要预留有足够的内存空间给用户线程使用,因此CMS收集器不能像其他收集器那样等到老年代几乎完全被填满了再进行收集,需要预留一部分空间提供并发收集时的程序运作使用。
- 在JDK1.5的默认设置下,CMS收集器当老年代使用了68%的空间后就会被激活,这是一个偏保守的设置,如果在应用中老年代增长不是太快,可以适当调高参数-XX:CMSInitiatingOccupancyFraction的值来提高触发百分比,以便降低内存回收次数从而获取更好的性能。
- 在JDK1.6中,CMS收集器的启动阈值已经提升至92%。要是CMS运行期间预留的内存无法满足程序需要,就会出现一次“Concurrent Mode Failure”失败,这时虚拟机将启动后备预案:临时启动Serial Ol收集器来重新进行老年代的垃圾收集,这样停顿时间就很长了。所以说参数-XX:CMSInitiatingOccupancyFraction设置得太高很容易导致大量“Concurrent Mode Failure”失败,性能反而降低。
-
CMS是一款基于“标记-清除”算法实现的收集器,这意味着收集结束时会有大量空间碎片产生。
- 空间碎片过多时,将会给大对象分配带来很大麻烦,往往会出现老年代还有很大空间剩余,但是无法找到足够大的连续空间来分配当前对象,不得不提前触发一次Full GC。
- 为了解决这个问题,CMS收集器提供了一个-XX:+UseCMSCompactAtFullCollection开关参数(默认是开启的),用于在CMS收集器顶不住要进行FullGC时开启内存碎片的合并整理过程,内存整理的过程是无法并发的,空间碎片问题没有了,但停顿时间不得不变长。
- 虚拟机设计者还提供了另外一个参数-XX:CMSFullGCsBeforeCompaction,这个参数是用于设置执行多少次不压缩的Full GC后,跟着来一次带压缩的(默认值为0,表示每次进入Full GC时都进行碎片整理)。
5 G1收集器
G1(Garbage-First),它是一款面向服务端应用的垃圾收集器,在多 CPU 和大内存的场景下有很好的性能。HotSpot 开发团队赋予它的使命是未来可以替换掉 CMS 收集器。
堆被分为新生代和老年代,其它收集器进行收集的范围都是整个新生代或者老年代,而 G1 可以直接对新生代和老年代一起回收。
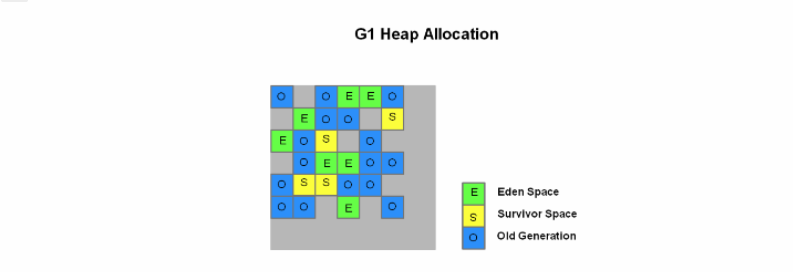
G1 把堆划分成多个大小相等的独立区域(Region),新生代和老年代不再物理隔离。
通过引入 Region 的概念,从而将原来的一整块内存空间划分成多个的小空间,使得每个小空间可以单独进行垃圾回收。这种划分方法带来了很大的灵活性,使得可预测的停顿时间模型成为可能。通过记录每个 Region 垃圾回收时间以及回收所获得的空间(这两个值是通过过去回收的经验获得),并维护一个优先列表,每次根据允许的收集时间,优先回收价值最大的 Region,这也是 G1 (Garbage-First) 名称的来由。每个 Region 都有一个 Remembered Set,用来记录该 Region 对象的引用对象所在的 Region。通过使用 Remembered Set,在做可达性分析的时候就可以避免全堆扫描。
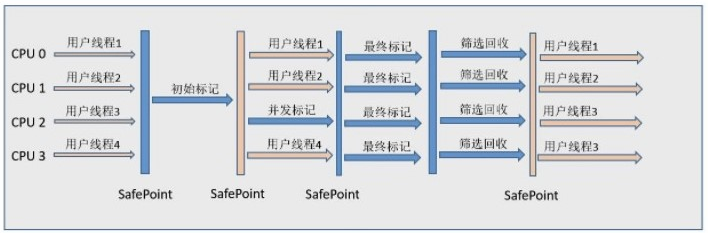
如果不计算维护 Remembered Set 的操作,G1 收集器的运作大致可划分为以下几个步骤:
- 初始标记:仅仅只是标记一下GC Roots能直接关联的对象,并且修改TAMS(Next Top at Mark Start)的值,让下一阶段用户程序并发执行运行时,能在正确可用的Tegion中创建新对象,这阶段需要停顿线程,单耗时很短。
- 并发标记:从GC Root开始对堆中的对象进行可达性性分析,找出存活的对象,这阶段耗时较长,但可与用户程序吧并发执行。
- 最终标记:为了修正在并发标记期间因用户程序继续运作而导致标记产生变动的那一部分标记记录,虚拟机将这段时间对象变化记录在线程的
Remembered Set Logs里面,最终标记阶段需要把Remembered Set Logs的数据合并到Remembered Set中。这阶段需要停顿线程,但是可并行执行。 - 筛选回收:首先对各个
Region中的回收价值和成本进行排序,根据用户所期望的GC停顿时间来制定回收计划。此阶段其实也可以做到与用户程序一起并发执行,但是因为只回收一部分Region,时间是用户可控制的,而且停顿用户线程将大幅度提高收集效率。
具备如下特点:
- 并行与并发:G1 能够利用多CPU、多核优势,缩短 STW(Stop The World)的时间,部分其它收集器原本需要停顿 Java 线程执行的 GC 操作,G1 收集器仍然可以通过并发的方式让 Java 程序继续执行。
- 分代收集: 分代概念在 G1 中仍然保留,虽然 G1 可以不需要其他收集器配合就能独立管理整个 GC 堆,但它仍然能够采取不同的方式去处理新创建的对象和已经存活了一段时间、熬过多次 GC 的旧对象以获取更好的效果。
- 空间整合:整体来看是基于 标记 - 整理 算法实现的收集器,从局部(两个 Region 之间)上来看是基于 复制 算法实现的,这意味着运行期间不会产生内存空间碎片。
- 可预测的停顿:能让使用者明确指定在一个长度为 M 毫秒的时间片段内,消耗在 GC 上的时间不得超过 N 毫秒。
4.7.4 内存分配与回收策略
1. Minor GC与Full GC
Minor GC:指发生在新生代上的垃圾收集动作,因为新生代对象存活时间很短,因此Minor GC会频繁执行,执行的速度一般也会比较快。Full GC(Major GC):指发生在老年代的GC,出现了Major GC,经常会伴随至少一次的Minor GC(但非绝对,在Parallel Scavenge收集器的收集策略中就有直接进行Major GC的策略选择过程)。Major GC的速度一般会比Minor GC慢10倍以上。
2.内存分配策略
-
对象优先在
Eden分配。大多数情况下,对象在新生代Eden区分配,当Eden区空间不够时,发起Minor GC。 -
大对象直接进入老年代。大对象是指需要连续内存空间的对象,最典型的大对象是那种很长的字符串以及数组。经常出现大对象会提前触发垃圾收集以获取足够的连续空间分配给大对象。
-XX:PretenureSizeThreshold,大于此值的对象直接在老年代分配,避免在Eden区和Survivor区之间的大量内存复制。 -
长期存活的对象进入老年代。为对象定义年龄计数器,对象在
Eden出生并经过Minor GC依然存活,将移动到Survivor中,年龄就增加 1 岁,增加到一定年龄则移动到老年代中。-XX:MaxTenuringThreshold用来定义年龄的阈值。 -
动态对象年龄判定。虚拟机并不是永远地要求对象的年龄必须达到
MaxTenuringThreshold才能晋升老年代,如果在Survivor中相同年龄所有对象大小的总和大于Survivor空间的一半,则年龄大于或等于该年龄的对象可以直接进入老年代,无需等到MaxTenuringThreshold中要求的年龄。 -
空间分配担保。在发生
Minor GC之前,虚拟机先检查老年代最大可用的连续空间是否大于新生代所有对象总空间,如果条件成立的话,那么Minor GC可以确认是安全的。如果不成立的话虚拟机会查看HandlePromotionFailure设置值是否允许担保失败,如果允许那么就会继续检查老年代最大可用的连续空间是否大于历次晋升到老年代对象的平均大小,如果大于,将尝试着进行一次Minor GC;如果小于,或者HandlePromotionFailure设置不允许冒险,那么就要进行一次Full GC。
3.Full GC的触发条件
对于 Minor GC,其触发条件非常简单,当 Eden 空间满时,就将触发一次 Minor GC。而 Full GC 则相对复杂,有以下条件:
-
调用System.gc( )。只是建议虚拟机执行
Full GC,但是虚拟机不一定真正去执行。不建议使用这种方式,而是让虚拟机管理内存。 -
老年代空间不足。老年代空间不足的常见场景为前文所讲的大对象直接进入老年代、长期存活的对象进入老年代等。为了避免以上原因引起的
Full GC,应当尽量不要创建过大的对象以及数组。除此之外,可以通过-Xmn虚拟机参数调大新生代的大小,让对象尽量在新生代被回收掉,不进入老年代。还可以通过-XX:MaxTenuringThreshold调大对象进入老年代的年龄,让对象在新生代多存活一段时间。 -
空间分配担保失败。使用复制算法的
Minor GC需要老年代的内存空间作担保,如果担保失败会执行一次Full GC。具体内容请参考上面的第五小节。 -
JDK1.7及以前的永久代空间不足。在
JDK 1.7及以前,HotSpot虚拟机中的方法区是用永久代实现的,永久代中存放的为一些 Class 的信息、常量、静态变量等数据。当系统中要加载的类、反射的类和调用的方法较多时,永久代可能会被占满,在未配置为采用CMS GC的情况下也会执行Full GC。如果经过Full GC仍然回收不了,那么虚拟机会抛出java.lang.OutOfMemoryError。为避免以上原因引起的Full GC,可采用的方法为增大永久代空间或转为使用CMS GC。 -
Concurrent Mode Failure。执行
CMS GC的过程中同时有对象要放入老年代,而此时老年代空间不足(可能是 GC 过程中浮动垃圾过多导致暂时性的空间不足),便会报Concurrent Mode Failure错误,并触发Full GC。
5 设计模式
面向对象开发的六原则一法则:
- 单一原则:就一个类而言,应该只专注于做一件事和仅有一个引起它变化的原因,实现高内聚。
- 开放封闭:软件实体应当对扩展开放,对修改关闭。要做到开闭有两个要点:①抽象是关键,一个系统中如果没有抽象类或接口系统就没有扩展点;②封装可变性,将系统中的各种可变因素封装到一个继承结构中,如果多个可变因素混杂在一起,系统将变得复杂而换乱。
- 依赖倒置原则: 高层模块不应该依赖于低层模块,二者都应该依赖于抽象;抽象不应该依赖于细节,细节应该依赖于抽象。即面向接口编程。该原则说得直白和具体一些就是声明方法的参数类型、方法的返回类型、变量的引用类型时,尽可能使用抽象类型而不用具体类型,因为抽象类型可以被它的任何一个子类型所替代。
- 任何变量都不应该持有一个指向具体类的指针或者引用;
- 任何类都不应该从具体类派生;
- 任何方法都不应该覆写它的任何基类中的已经实现的方法。
- 里氏替换原则:子类对象必须能够替换掉所有父类对象。简单的说就是能用父类型的地方就一定能使用子类型,子类一定是增加父类的能力而不是减少父类的能力,因为子类比父类的能力更多,把能力多的对象当成能力少的对象来用当然没有任何问题。
- 接口隔离原则:接口要小而专,绝不能大而全.臃肿的接口是对接口的污染,既然接口表示能力,那么一个接口只应该描述一种能力,接口也应该是高度内聚的。
- 合成聚合复用原则:优先使用聚合或合成关系复用代码。
- 迪米特法则:迪米特法则又叫最少知识原则,一个对象应当对其他对象有尽可能少的了解。迪米特法则简单的说就是如何做到"低耦合",门面模式和调停者模式就是对迪米特法则的践行。
介绍:中文译名:设计模式 - 可复用的面向对象软件元素) 中所提到的,总共有 23 种设计模式。这些模式可以分为三大类:创建型模式(Creational Patterns)、结构型模式(Structural Patterns)、行为型模式(Behavioral Patterns)。当然,我们还会讨论另一类设计模式:J2EE 设计模式。

5.1 单例模式
单例模式有以下特点:单例模式的定义,官方的定义总结起来就两句话,确保一个类只有一个实例(也就是类的对象),并且提供一个全局的访问点(外部通过这个访问点来访问该类的唯一实例)。
- 单例类只能有一个实例。
- 单例类必须自己创建自己的唯一实例,并给所有其他对象提供这一实例。
优点: 1、在内存里只有一个实例,减少了内存的开销,尤其是频繁的创建和销毁实例(比如管理学院首页页面缓存)。
2、避免对资源的多重占用(比如写文件操作)。
缺点: 没有接口,不能继承,与单一职责原则冲突,一个类应该只关心内部逻辑,而不关心外面怎么样来实例化。
使用场景:
-
1、要求生产唯一序列号。
-
2、WEB 中的计数器,不用每次刷新都在数据库里加一次,用单例先缓存起来。
-
3、创建的一个对象需要消耗的资源过多,比如 I/O 与数据库的连接等。
5.1.1 饿汉式实现
public class Singleton{
private static Singleton singleton=new Singleton();//主动创建
private Singleton(){}//私有构造方法
public static Singleton getInstance(){//提供全局的获取方法
return singleton;
}
}
5.1.2 懒汉实现
public class Singleton{
private static Singleton singleton;//先定义
private Singleton(){}//私有构造方法
public static Singleton getInstance(){
if(singleton==null){//需要用的时候才去创建
singleton=new Singleton();
}
return singleton;
}
}
5.1.3懒汉式线程安全实现
public class Singleton{
private static Singleton singleton;//先定义
private Singleton(){}//私有构造方法
public static synchronized Singleton getInstance(){
if(singleton==null){
singleton=new Singleton();
}
return singleton;
}
}
public class Singleton{
private static Singleton singleton;//先定义
private Singleton(){}//私有构造方法
public static Singleton getInstance(){
synchronized(Singleton.class){
if(singleton==null){
singleton=new Singleton();
}
}
return singleton;
}
}
5.1.4 双检锁/双重校验锁(DCL,即double-checked locking)
public class Singleton{
private static Singleton singleton;//先定义
private Singleton(){}//私有构造方法
public static Singleton getInstance(){
if(singleton==null){//在线程安全的懒汉式上增加一个判空
synchronized(Singleton.class){
if(singleton==null){
singleton=new Singleton();
}
}
}
return singleton;
}
5.1.5 登记式/静态内部类
这种方式能达到双检锁方式一样的功效,但实现更简单。对静态域使用延迟初始化,应使用这种方式而不是双检锁方式。这种方式只适用于静态域的情况,双检锁方式可在实例域需要延迟初始化时使用。
这种方式同样利用了 classloader 机制来保证初始化 instance 时只有一个线程,它跟第 3 种方式不同的是:第 3 种方式只要 Singleton 类被装载了,那么 instance 就会被实例化(没有达到 lazy loading 效果),而这种方式是 Singleton 类被装载了,instance 不一定被初始化。因为 SingletonHolder 类没有被主动使用,只有通过显式调用 getInstance 方法时,才会显式装载 SingletonHolder 类,从而实例化 instance。
public class Singleton{
private static class SingletonHolder{//创建内部类,提供唯一实例
private static final Singleton INSTANCE=new Singleton();
}
private Singleton(){}
public static final Singleton getInstance(){
return SingleonHolder.INSTANCE;//返回内部类唯一静态参数
}
}
5.1.6 枚举
这种实现方式还没有被广泛采用,但这是实现单例模式的最佳方法。它更简洁,自动支持序列化机制,绝对防止多次实例化。
这种方式是 Effective Java 作者 Josh Bloch 提倡的方式,它不仅能避免多线程同步问题,而且还自动支持序列化机制,防止反序列化重新创建新的对象,绝对防止多次实例化。
public enum Singleton{
INSTANCE;
public viod whateverMethod(){
}
}
5.2 工厂模式
**意图:**定义一个创建对象的接口,让其子类自己决定实例化哪一个工厂类,工厂模式使其创建过程延迟到子类进行。
**主要解决:**主要解决接口选择的问题。
**何时使用:**我们明确地计划不同条件下创建不同实例时。
**如何解决:**让其子类实现工厂接口,返回的也是一个抽象的产品。
**关键代码:**创建过程在其子类执行。
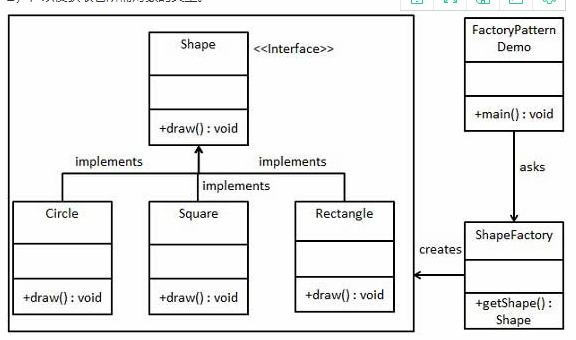
//步骤一:创建一个接口
//Shape.java
public interface Shap{
void draw();
}
//步骤二:创建实现接口的实体类
//Rectangle.java
public class Rectangle implements Shape{
@Override
public void draw() {
System.out.println("Inside Rectangle::draw() method.");
}
}
//Square,java
public class Square implements Shape{
@Override
public void draw() {
System.out.println("Inside Square::draw() method.");
}
}
//Circle.java
public class Circle implements Shape {
@Override
public void draw() {
System.out.println("Inside Circle::draw() method.");
}
}
//步骤三:创建一个工厂,生成基于给定信息的实体类的对象
public calss ShapeFactory{
public Shape getShape(String shapeType){
if(shapeType==null)
return null;
}
if(shapeType.equalsIgnoreCase("CIRCLE")){
return new Circle();
} else if(shapeType.equalsIgnoreCase("RECTANGLE")){
return new Rectangle();
} else if(shapeType.equalsIgnoreCase("SQUARE")){
return new Square();
}
return null;
}
//步骤四:使用工厂,通过传递类型信息来获取实体类的对象
public class FactoryPatternDemo {
public static void main(String[] args) {
ShapeFactory shapeFactory = new ShapeFactory();
//获取 Circle 的对象,并调用它的 draw 方法
Shape shape1 = shapeFactory.getShape("CIRCLE");
//调用 Circle 的 draw 方法
shape1.draw();
Shape shape2 = shapeFactory.getShape("RECTANGLE");
shape2.draw();
Shape shape3 = shapeFactory.getShape("SQUARE");
shape3.draw();
}
}
5.3 抽象工厂模式
抽象工厂模式(Abstract Factory Pattern)是围绕一个超级工厂创建其他工厂。该超级工厂又称为其他工厂的工厂。这种类型的设计模式属于创建型模式,它提供了一种创建对象的最佳方式。
在抽象工厂模式中,接口是负责创建一个相关对象的工厂,不需要显式指定它们的类。每个生成的工厂都能按照工厂模式提供对象。
**意图:**提供一个创建一系列相关或相互依赖对象的接口,而无需指定它们具体的类。
**主要解决:**主要解决接口选择的问题。
**何时使用:**系统的产品有多于一个的产品族,而系统只消费其中某一族的产品。
**如何解决:**在一个产品族里面,定义多个产品。
**关键代码:**在一个工厂里聚合多个同类产品。
**优点:**当一个产品族中的多个对象被设计成一起工作时,它能保证客户端始终只使用同一个产品族中的对象。
**缺点:**产品族扩展非常困难,要增加一个系列的某一产品,既要在抽象的 Creator 里加代码,又要在具体的里面加代码。
使用场景: 1、QQ 换皮肤,一整套一起换。 2、生成不同操作系统的程序。
**注意事项:**产品族难扩展,产品等级易扩展。
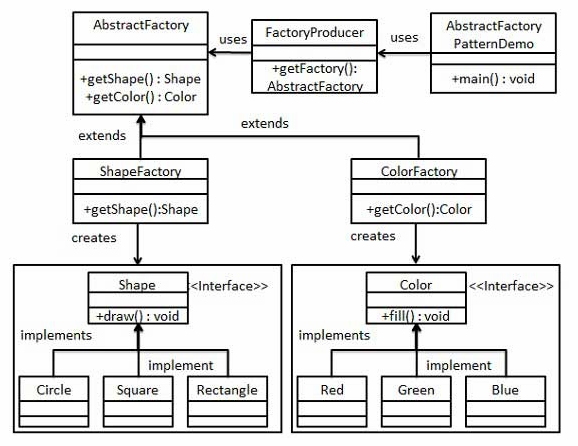
//步骤一:为形状创建一个接口
//Shap.java
public interface Shap{
void draw();
}
//步骤二:创建实现接口的实体类
//Rectangle.java
public class Rectangle implements Shape{
@Override
public void draw() {
System.out.println("Inside Rectangle::draw() method.");
}
}
//Square,java
public class Square implements Shape{
@Override
public void draw() {
System.out.println("Inside Square::draw() method.");
}
}
//Circle.java
public class Circle implements Shape {
@Override
public void draw() {
System.out.println("Inside Circle::draw() method.");
}
}
//步骤三:为颜色创建一个接口
//Color.java
public interface Color{
void fill();
}
//步骤四:创建实现接口的实体类
//Red.java
public class Red implements Color {
@Override
public void fill() {
System.out.println("Inside Red::fill() method.");
}
}
//Green.java
public class Green implements Color {
@Override
public void fill() {
System.out.println("Inside Green::fill() method.");
}
}
//Blue.java
public class Blue implements Color {
@Override
public void fill() {
System.out.println("Inside Blue::fill() method.");
}
}
//步骤五:为Color和Shape对象创建抽象类来获取工厂
//AbstractFactory.java
public abstract class AbstractFactory {
public abstract Color getColor(String color);
public abstract Shape getShape(String shape);
}
//步骤六:创建扩展了 AbstractFactory 的工厂类,基于给定的信息生成实体类的对象。
//ShapeFactory.java
public class ShapeFactory extends AbstractFactory {
@Override
public Shape getShape(String shapeType){
if(shapeType == null){
return null;
}
if(shapeType.equalsIgnoreCase("CIRCLE")){
return new Circle();
} else if(shapeType.equalsIgnoreCase("RECTANGLE")){
return new Rectangle();
} else if(shapeType.equalsIgnoreCase("SQUARE")){
return new Square();
}
return null;
}
@Override
public Color getColor(String color) {
return null;
}
}
//ColorFactory.java
public class ColorFactory extends AbstractFactory {
@Override
public Shape getShape(String shapeType){
return null;
}
@Override
public Color getColor(String color) {
if(color == null){
return null;
}
if(color.equalsIgnoreCase("RED")){
return new Red();
} else if(color.equalsIgnoreCase("GREEN")){
return new Green();
} else if(color.equalsIgnoreCase("BLUE")){
return new Blue();
}
return null;
}
}
//步骤七:创建一个工厂创造器/生成器类,通过传递形状或颜色信息来获取工厂
//FactoryProducer.java
public class FactoryProducer {
public static AbstractFactory getFactory(String choice){
if(choice.equalsIgnoreCase("SHAPE")){
return new ShapeFactory();
} else if(choice.equalsIgnoreCase("COLOR")){
return new ColorFactory();
}
return null;
}
}
//步骤八:使用 FactoryProducer 来获取 AbstractFactory,通过传递类型信息来获取实体类的对象。
//AbstractFactoryPatternDemo.java
public class AbstractFactoryPatternDemo {
public static void main(String[] args) {
//获取形状工厂
AbstractFactory shapeFactory = FactoryProducer.getFactory("SHAPE");
//获取形状为 Circle 的对象
Shape shape1 = shapeFactory.getShape("CIRCLE");
//调用 Circle 的 draw 方法
shape1.draw();
//获取形状为 Rectangle 的对象
Shape shape2 = shapeFactory.getShape("RECTANGLE");
//调用 Rectangle 的 draw 方法
shape2.draw();
//获取形状为 Square 的对象
Shape shape3 = shapeFactory.getShape("SQUARE");
//调用 Square 的 draw 方法
shape3.draw();
//获取颜色工厂
AbstractFactory colorFactory = FactoryProducer.getFactory("COLOR");
//获取颜色为 Red 的对象
Color color1 = colorFactory.getColor("RED");
//调用 Red 的 fill 方法
color1.fill();
//获取颜色为 Green 的对象
Color color2 = colorFactory.getColor("Green");
//调用 Green 的 fill 方法
color2.fill();
//获取颜色为 Blue 的对象
Color color3 = colorFactory.getColor("BLUE");
//调用 Blue 的 fill 方法
color3.fill();
}
}
5.4 建造者模式
建造者模式(Builder Pattern)使用多个简单的对象一步一步构建成一个复杂的对象。这种类型的设计模式属于创建型模式,它提供了一种创建对象的最佳方式。一个 Builder 类会一步一步构造最终的对象。该 Builder 类是独立于其他对象的。
**意图:**将一个复杂的构建与其表示相分离,使得同样的构建过程可以创建不同的表示。
**主要解决:**主要解决在软件系统中,有时候面临着"一个复杂对象"的创建工作,其通常由各个部分的子对象用一定的算法构成;由于需求的变化,这个复杂对象的各个部分经常面临着剧烈的变化,但是将它们组合在一起的算法却相对稳定。
**何时使用:**一些基本部件不会变,而其组合经常变化的时候。
**如何解决:**将变与不变分离开。
**关键代码:**建造者:创建和提供实例,导演:管理建造出来的实例的依赖关系。
应用实例: 1、去肯德基,汉堡、可乐、薯条、炸鸡翅等是不变的,而其组合是经常变化的,生成出所谓的"套餐"。 2、JAVA 中的 StringBuilder。
优点: 1、建造者独立,易扩展。 2、便于控制细节风险。
缺点: 1、产品必须有共同点,范围有限制。 2、如内部变化复杂,会有很多的建造类。
使用场景: 1、需要生成的对象具有复杂的内部结构。 2、需要生成的对象内部属性本身相互依赖。
**注意事项:**与工厂模式的区别是:建造者模式更加关注与零件装配的顺序。
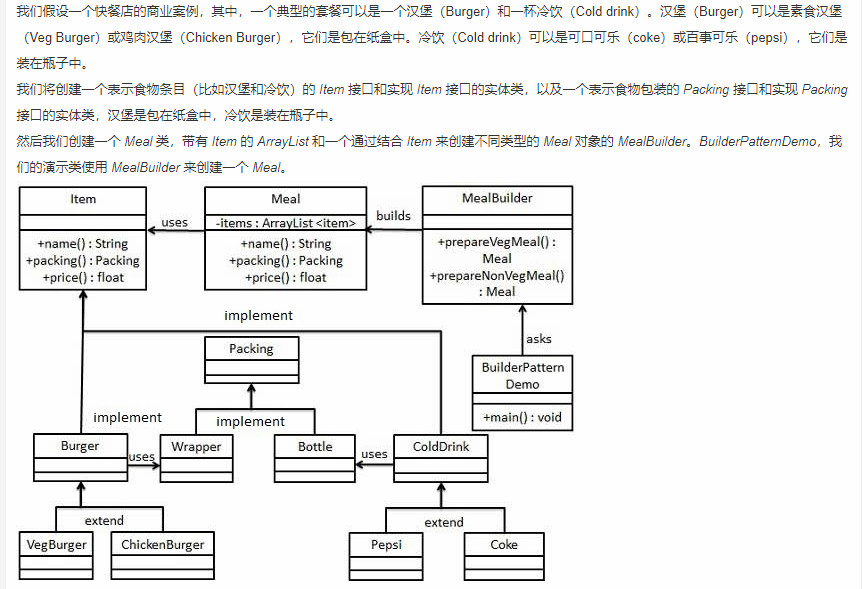
 支付宝
支付宝  微信
微信